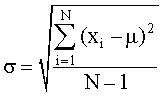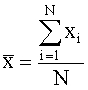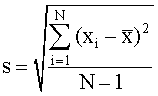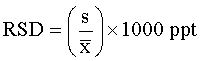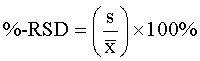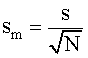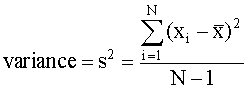If data values are all equal to one another, then the standard deviation is zero.
If a high proportion of data points lie near the mean value, then the standard deviation is small. An experiment that yields data with a low standard deviation is said have high precision.
If a high proportion of data points lie far from the mean value, then the standard deviation is large. An experiment that yields data with a high standard deviation is said to have low precision.
The following quantities/equations are quantitative measures of precision.
The equations provide precision measures for a limited number of repetitive measurements, i.e. between 2 and 20. The equation at the end is the true standard deviation for any number of repeat measurements.
The mean or average, 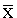 , is calculated from:
, is calculated from: Where N is the number of measurements and xi is each individual measurement. is sometimes called the sample mean to differentiate it from the true orpopulation mean, μ. The formula for μ is the same as above, but N must be at least 20 measurements. Standard Deviation
The standard deviation, s, is a statistical measure of the precision for a series of repetitive measurements. The advantage of using s to quote uncertainty in a result is that it has the same units as the experimental data. Under a normal distribution, ± one standard deviation encompasses 68% of the measurements and ± two standard deviations encompasses 96% of the measurements. It is calculated from:
Where N is the number of measurements, xi is each individual measurement, and is the mean of all measurements. The quantity (xi - ) is called the "residual" or the "deviation from the mean" for each measurement. The quantity (N - 1) is called the "degrees of freedom" for the measurement.Relative standard Deviation
The relative standard deviation (RSD) is useful for comparing the uncertainty between different measurements of varying absolute magnitude. The RSD is calculated from the standard deviation, s, and is commonly expressed as parts per thousand (ppt) or percentage (%):
The %-RSD is also called the "coefficient of variance" or CV.
Confidence Limits
Confidence limits are another statistical measure of the precision for a series of repetitive measurements. They are calculated from the standard deviation using:
You would say that with some confidence, for example 95%, the true value is between the confidence limits. The t term is taken from a table for the number of degrees of freedom and the degree of confidence desired. t values for finding confidence limits D.F. 90% 95% 99% 16.3112.7163.6622.924.309.9332.353.185.8442.132.784.6052.012.574.0361.942.453.7171.902.373.50151.752.132.95  1.651.962.58
1.651.962.58 You might also encounter the term "confidence interval".
The confidence interval is the span between the confidence limits:Other Measures of Precision
The quantitative measures of precision described above are the most common for reporting analytical results. You might encounter other measures of precisions, and several other quantities are listed here for completeness.
Standard Error
The advantage of working with variance is that variances from independent sources of variation may be summed to obtain a total variance for a measurement.
All of the equations above are intended to obtain the precision of a relatively small numbers of repeated measurements. For 20 or more measurements you need to use:
The True or Population Standard Deviation
This is given the symbol sigma:
The equation is: